
Tom Herbert, SiPanda CTO, August 19, 2024.
Last time we introduced the basics of protocol parsing, this time we’ll dive into the mechanics. With the fundamental mechanics of parsing established we’ll be able to elicit the design and implementation for highly efficient parsers in both software and hardware.
Top-level protocols and sub-protocols
With respect to parsing, let's make a distinction between top-level protocols and sub-protocols.
Top-level protocols are what we typically think of Layer 2 to Layer 7 protocols. These include IPv4/6, TCP, UDP, QUIC, HTTP/2, and so on. In order to parse top level protocols, we need to derive two pieces of information– the length of the protocol header and the type of the next protocol header for a non-leaf protocol.
In contrast to top-level protocols, sub-protocols are protocol constructs within top-level protocols. Sub-protocols include TLVs like TCP options, flag-fields like in GRE, and arrays like the segment list in SRV6. Sub-protocols are always parsed in the context of their encapsulating top level protocol. For instance, TCP specifies the rules about how TCP options are parsed and where in the TCP header options start. Like parsing top-level protocols, when parsing a sub-protocol we need to derive two pieces of information: the length of each sub-protocol header and its type. Note the subtle difference here, for top-level protocols it’s the type of the next protocol header we need for non-leaf protocols, but in sub-protocols the type is for the current sub-protocol header being parsed. So sub-protocols, such as TLVs, are self identifying– for example the first byte of a TCP option gives the option type and the second byte gives the option length.
Parsing top-level protocols
Previously, we boiled down top-level protocol parsing to be: 1) identify the protocol of each protocol header in a packet, 2) verify and optionally process the header, 3) and then proceed to the next header. We’ll add a few optional step for a complete process:
Parse and process any sub-protocols of a top-level protocol header. For instance, when a TCP header is parsed, we can also parse the TCP options within the header
Perform metadata extraction. When we parse a protocol header, it is convenient to save certain fields in a protocol header into a memory buffer for consumption by later processing. For instance, the parser might record IPv4 addresses into a metadata buffer when parsing the IPv4 header
Run a protocol handler. This is to perform backend processing for a protocol. For instance, we may terminate TCP connections and process the TCP state machine in backend processing. This processing can be done by scheduling a thread to run in parallel with the parser (as form of vertical parallelism)
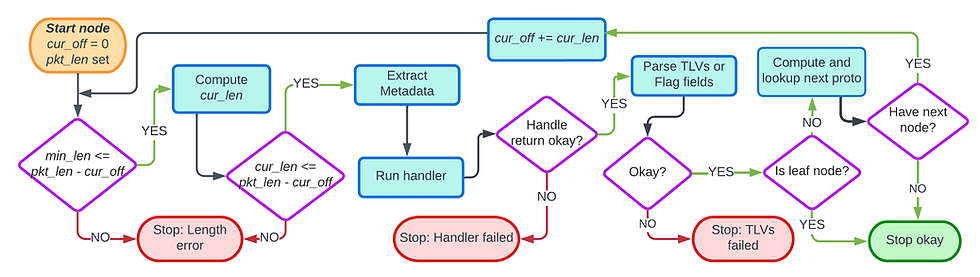
Parsing is inherently a serialized operation where we need to parse each protocol header of a packet in order. When the parser, runs we call the header currently being processed the current header (gee, there’s a surprise :-) ). For clarity of the description, we define a few state variables for parsing:
pkt_base_ptr: Address pointer to the first byte of the packet
pkt_len: Byte length of the packet
cur_off: The offset of the first byte of the current protocol header being parsed. The offset is relative to the start of the packet
cur_len: Length of the current protocol header being parsed
cur_ptr: Address pointer to the first byte of the current protocol header being parsed. This is equal to pkt_base_ptr + cur_offset
min_len: The minimum length of a protocol header. This is a constant value per protocol, for instance the minimum length of the IPv4 header is twenty bytes
The diagram below gives the flow chart for parsing one top level protocol header. Processing of all the headers is performed in a loop that terminates when a non-leaf protocol is encountered.
Parsing TLVs
Type Length Values, or just TLVs, are a common sub-protocol construct for encoding a list of optional variable length data. As we mentioned TLVs are self identifying where they contain a type field and length field. Multiple TLVs form a list of TLVs the list is parsed by parsing each TLV in the list in order.
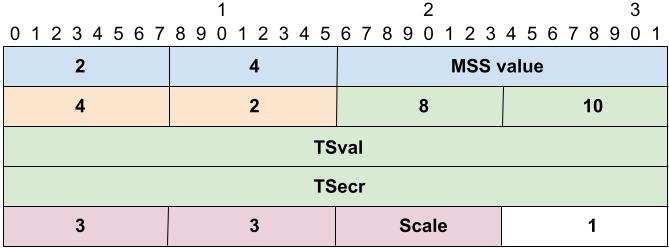
Example of TCP options. This diagram shows a list of TCP options that might be in a SYN packet. The first byte of each option the Kind and the second is the length.There are four options: MSS (kind 2, length 4), SACK Permitted (kind 4, length 2), Timestmaps (kind 8, length 10), and Windows Scaling (kind 3, length 3). The trailing byte with a value of 1 is special option for No-operation (i.e. it's padding)
The procedures for parsing TLVs are similar to those for paring top-level protocols. The basic steps are: 1) identify the type of each TLV in the list of TLVs, 2) verify and optionally process the TLV, 3) and then proceed to the next TLV. For each TLV we can also perform metadata extraction and do backend processing of the TLV.
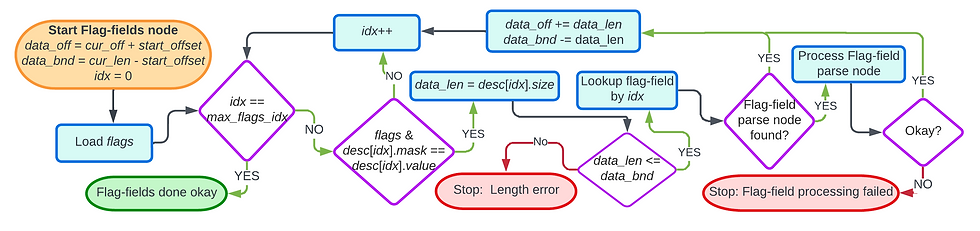
Processing a list of TLVs is a serialized operation, we need to process them in order and since they’re variable length there’s no random access (for instance, we can’t just jump to the 5th TLV in a list, we need to at least parse the first four to get to get to the fifth). So when parsing TLVs there is a concept of a current TLV being parsed, we call this the data header (this is a general concept for sub-protocols). With that, we define some state variables for parsing TLVs:
start_offset: The offset of the first byte of TLVs in the top level protocol. For instance, the start_offset for TCP options would be cur_offset + 20
data_off: The offset of the first byte of the current TLV being parsed. The offset is relative to the start of the packet
data_len: Length of the current TLV being parsed
data_bnd: Maximum allowed size of the current TLV. For typical protocols, like TCP and IPv4 where the TLVs follow a base header, this is equal to cur_off + cur_len - data_off
data_ptr: Address pointer to the first byte of the current protocol header being parsed. This is equal to pkt_base_ptr + data_offset
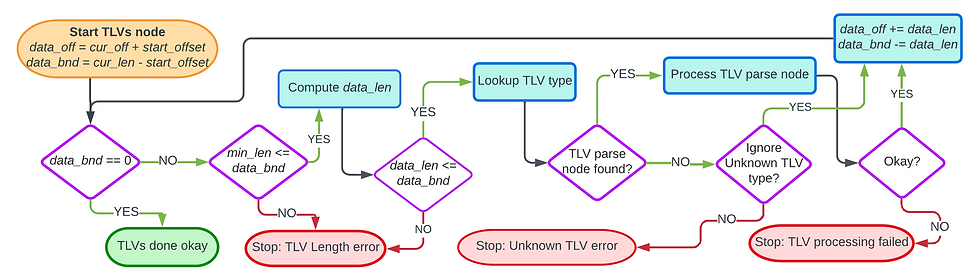
The diagram below gives the flow chart for parsing one TLV. TLVs are parsed in a loop that is terminated when the we reach the end of the space for TLVs (data_bnd becomes zero).
Parsing flag-fields
Flag-fields are an interesting protocol construct for encoding optional data in a protocol header. The basic idea is that the protocol contains a set of flag bits, and when a bit is set that indicates the presence of a field. The field for a bit that is used in GRE and some other protocols including GUE. The diagram below shows flag-fields in GRE.
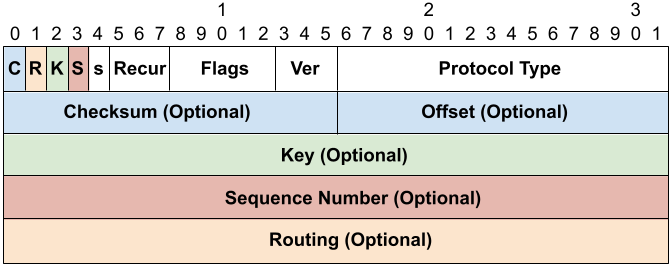
Flag-fields in GRE. This diagram shows the GRE header. If the C bit is set then the Checksum (and Offset) fields are present, if the R bit is set then the Routing field is present, if the K bit is set then Key field is present, and if the S bit is set then the Sequence Number field is present
Parsing flag-fields is a bit different than top-level protocols or TLVs. The set of flags permits random access to the fields. If a bit for some field is set then we can compute its offset in the packet by summing up the sizes of fields that precede the field we’re looking for. For instance, suppose in the case of GRE we are only interested in parsing the Key field whose presence is indicated by the K bit. If the K bit is set in the packet then we know the field is present and the offset of the corresponding field is either four or eight bytes depending on whether the C bit is set.
Now we can describe the mechanics for parsing flag fields. We’ll use an ancillary table called the flags table that maps flags to their sizes and is ordered by the order of the corresponding fields in the packet. The index of the flag in that table is used as a pseudo protocol number for looking up the flag for processing the field. We define some variables for parsing flag-fields:
start_offset: The offset of the first byte of fields in the top level protocol. This is constant per protocol. For instance, the start_offset for GRE fields is four
data_off: The offset of the first byte of fields in a packet. The offset is relative to the start of the packet
data_len: Length of the current field– this is a constant value for the flag definition
protocol TLV being parsed
data_bnd: Maximum allowed size of the current field. For typical protocols, like GRE and GUE where the fields follow a base header, this is equal to cur_off + cur_len - data_off
data_ptr: Address pointer to the first byte of the next field. This is equal to pkt_base_ptr + data_offset
The diagram below gives the flow chart for parsing one flag-field. Flag-fields are are parsed in a loop that is terminated when the reach the end of flags table.
SiPanda
SiPanda was created to rethink the network datapath and bring both flexibility and wire-speed performance at scale to networking infrastructure. The SiPanda architecture enables data center infrastructure operators and application architects to build solutions for cloud service providers to edge compute (5G) that don’t require the compromises inherent in today’s network solutions. For more information, please visit www.sipanda.io. If you want to find out more about PANDA, you can email us at panda@sipanda.io. IP described here is covered by patent USPTO 12,026,546 and other patents pending.
Opmerkingen