
Tom Herbert, SiPanda CTO, September 2, 2024
Let’s talk about how to make protocol parsing fly! As we pointed out previously, parsing is perhaps the most common operation in a networking stack. Every packet ever received needs to be parsed to some extent, so there’s a lot of motivation to optimize parsing for throughput, latency, and power. We also mentioned the importance of programmability in a network stack including for parsing. Putting these together, we want fast and efficient parsers that can be programmed on the fly to support a myriad of different protocols and constructs.
There have been a number of efforts for programmable and high performance parsing in specialized processors including Network Processor Units (NPUs) and more recently P4. While these have had some limited success, the fact is they have not achieved the ubiquity of CPUs and don’t have the same levels of programmability or flexibility. SiPanda took a radically different approach– we defined and implemented parser instructions for the CPU! Specifically, we extended the RISC-V Instruction Set Architecture (ISA) with a set of instructions specific to parsing. Conceptually, any CPU could be extended with parser instructions, however RISC-V presented the perfect opportunity for a first implementation due to its open ISA and simplicity of design. Parser instructions in RISC-V deliver both high performance and are eminently programmable!
Why the #$@&%*! do we need parser instructions?
Parser instructions in the CPU have a bunch of advantages over using specialized non-CPU processors, like NPUs and P4 processors or fixed function hardware:
Turing complete. Parser instructions are CPU instructions so they can be freely intermixed with other CPU instructions including integer instructions. The net effect is that parser instructions are effectively Turing complete and can parse any protocol.
Applicability. The SiPanda parser instructions can be used to optimize parsing over 99% of protocol parsing use cases before needing to fallback to integer instructions. This includes parsing of some of the more notoriously difficult to parse protocol constructs like TLVs, flag-fields, and Protocol Buffers (protobufs).
High performance. Individual parser instructions are quite powerful, replacing anywhere between five and three hundred plain CPU instructions. Working with the parser registers to keep state between instructions, the parser instructions have comparable performance with any non-CPU programmable processor solution.
Ease-of-use. Parser instructions are just another ISA extension and there's nothing particularly special about them from the developer point of view– that’s a good thing! They facilitate the use of common open source tool chains, standard debugging tools, and straightforward production support. We use the LLVM toolchain to emit instructions by decoupling the backend hardware target from the frontend programming language, thereby allowing the developer to program their parser in the language of their choosing. Parser instructions can be integrated into the rest of the developer's program so that they aren't restricted by any particular model (such as parse-match-action pipelines enforced in P4).
Simplicity. Parser instructions present a design simplification for system design. From a system point of view, they are just another CPU feature. For instance, instead of needing separate components for parser processors, parsing instructions can reside in existing CPUs that can do more than just parsing (like termination of transport protocols like TCP). Also, interconnects and memory interfaces don’t need to be reimagined for parser instructions.
Parser instruction design
SiPanda parser instructions are primarily comprised of::
A parser register file
Parser instructions (mnemonics and semantics)
Interactions and integration into the CPU
The parser register file contains thirty-two sixty-four bit registers that hold parser state, configuration, general purpose accumulators, and address targets. Parser instructions operate on these registers to perform parsing operations, and they interact with the core CPU by accessing the Load and Store Unit (LSU), affecting the Program Counter, and moving values between parser registers and integer registers. Each register has a readable name like CurHdr or PktLen and in assembly registers are denoted by p* like pcurhdr and ppktlen. Some of the registers have subfields like CurHdr which has CurHdr.Offset and CurHdr.Length subfields. The diagram below illustrates some of the key state values in the parser registers for basic parsing; note that these map one-to-one into the variables we introduced in our discussion of protocol parsing mechanics.
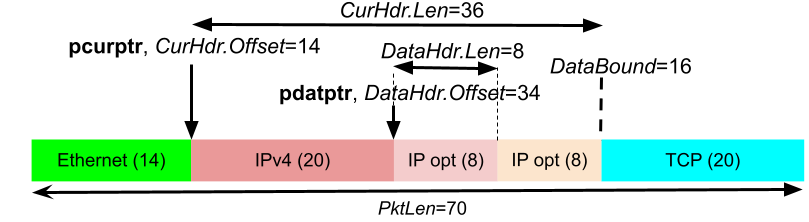
Parser state registers. This diagram shows an example of some of the key state registers used in parser instructions. In this example, an IP header with options is currently being parsed for TCP/IPv4 packet with seventy bytes of total length. The data header is set for parsing the first IP option. The key parser registers are shown with their values for this example.
Program flow
A parser is defined by a set of parse nodes that comprise a parse graph. Each node is compiled into a sequence of instructions which could be a combination of parser instructions and other instructions. Parser instructions are prefixed by prs. in the mnemonic, and the last instruction for the node is a “stop node” parser instruction which is denoted by the suffix .stp in the mnemonic. When a “stop node” instruction completes the program counter is changed to do a jump– the jump target might be next node in the parse graph, a parser exit handler (for either success or failure in parsing), or return to processing the higher layer node when processing for a sub-protocol like TLVs completes. The target of a “stop node” instruction is taken from the Next (pnext) register. The Next register can be set via CAM lookup or array lookup instructions, or can be set as a side effect of other parser instructions.
Parser instructions employ exceptions instead of using conditional branches, and several parser registers can be programmed with the address to process exception handlers. Exception handlers are treated like any other node, they are sequences of instructions terminated by a “stop node” instruction. For our purposes, we’ll mention two exception handlers: OkayTarget and FailTarget. OkayTarget indicates the address to jump to when the parser exits on success, and FailTarget is used when the parser exits due to an error condition where a code for the condition is set in the ExitCode register.
Example of parser instructions
Without further adieu, let’s jump into a program to show how the instructions work. In the assembly listing below, we look at a node for IPv4. IPv4 is an interesting example because it is both a Variable Length Header protocol and a non-leaf protocol.
ipv4_node:
1 prs.load.b paccum, pcurptr
2 prs.cmp.n paccum[0],4
3 prs.lensetmin.n pcurhdr,paccum[1],4:20
4 prs.load.b paccum,pcurptr+9
5 prs.cam.b.stp pnext,paccum
In Line 1, the first byte of the IPv4 header is loaded into the accumulator register (paccum). In Line 2, the IP version, the first nibble in the header, is checked to be equal to four; if it’s not equal to four then an exception is raised and a jump is made to FailTarget.
In Line 3, the IP header length is computed and verified by prs.lensetmin instruction. This instruction does several things: 1) The second nibble is left shifted by four to derive the IPv4 header length (standard IPv4 header length calculation), 2) The derived length is checked to be at least twenty which is the minimum length of an IPv4 header, 3) The derived length is checked to against the packet length, that is CurHdr.Offest plus the derived length must be less than or equal to PktLen, and 4) CurHdr.Length is set to the derived length value. If any of the length checks fail an exception is raised and a jump is made to FailTarget.
In Line 4, the single byte IP Protocol field is loaded from offset nine into the accumulator. In Line 5, a CAM lookup is performed on the IP Protocol. The instruction performs the lookup and sets the Next register. A CAM lookup operates on a preconfigured table, and in this example the CAM contains entries for various IP protocols such as TCP and UDP, for instance a TCP entry would have a key value of 6 and target value of the address of tcp_node. If an entry is matched in the lookup, for instance the packet is TCP and so protocol number 6 is matched, then Next is set with the address of the node. If the CAM lookup doesn’t have a match then Next is set with the address of an exception handler (this could be OkayTarget or FailTarget depending on whether a next protocol is required). The instruction at Line 6 is a “stop node” instrutcion as indicated by .stp so when processing completes a jump is made to an address determined by Next (for instance, the address of tcp_node for a TCP packet).
What’s next
With the basics of parser instructions under our belt, we can move into more advanced use cases including encapsulation, header overlays, TLV and flag-field processing, metadata extraction, and running threads for deep processing. We also will describe how the compiler model makes it easy on the programmer to write their parser and then how compilers convert their expression of intent into a highly optimized binary.
SiPanda
SiPanda was created to rethink the network datapath and bring both flexibility and wire-speed performance at scale to networking infrastructure. The SiPanda architecture enables data center infrastructure operators and application architects to build solutions for cloud service providers to edge compute (5G) that don’t require the compromises inherent in today’s network solutions. For more information, please visit www.sipanda.io. If you want to find out more about PANDA, you can email us at panda@sipanda.io. IP described here is covered by patent USPTO 12,026,546 and other patents pending.
Comments